Benchmark¶
Test device: E5 2680 v4, 14 core.
Package Comparison¶
This comparison for different packages ( gplearn, BindingGP) speed.
Test datasets: boston datasets from scikit-learn .
pop*gen times (s) |
fastgplearn |
gplearn |
BindingGP |
1000*10 |
0.15 |
4.91 |
29.09 |
10000*10 |
1.49 |
50.66 |
295.34 |
10000*10 (8 core) |
1.45 |
57.01 |
126.20 |
100000*10 |
15.8 |
490.00 |
3053.01 |
100000*10 (8 core) |
11.5 |
422.67 |
1452.58 |
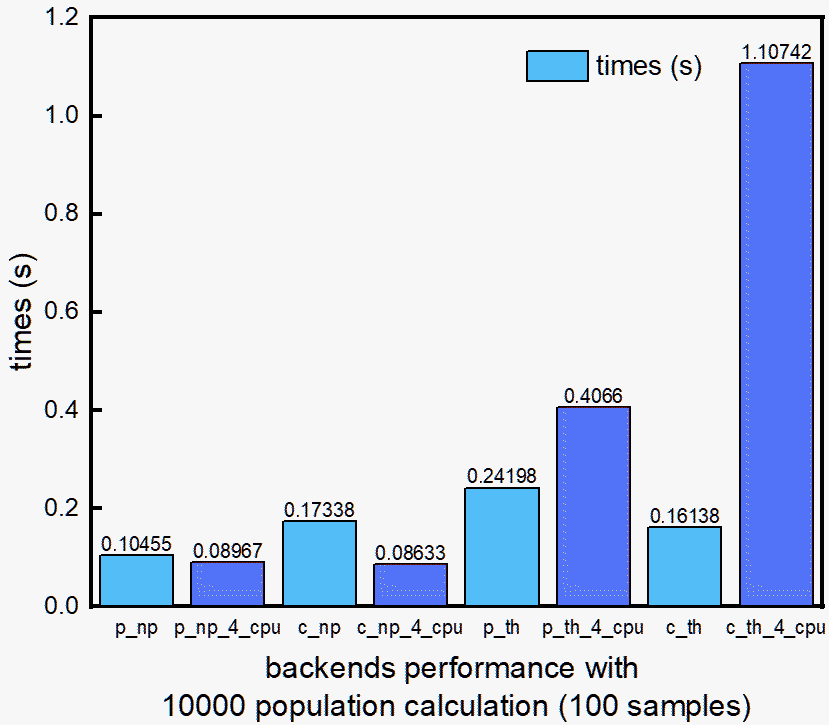
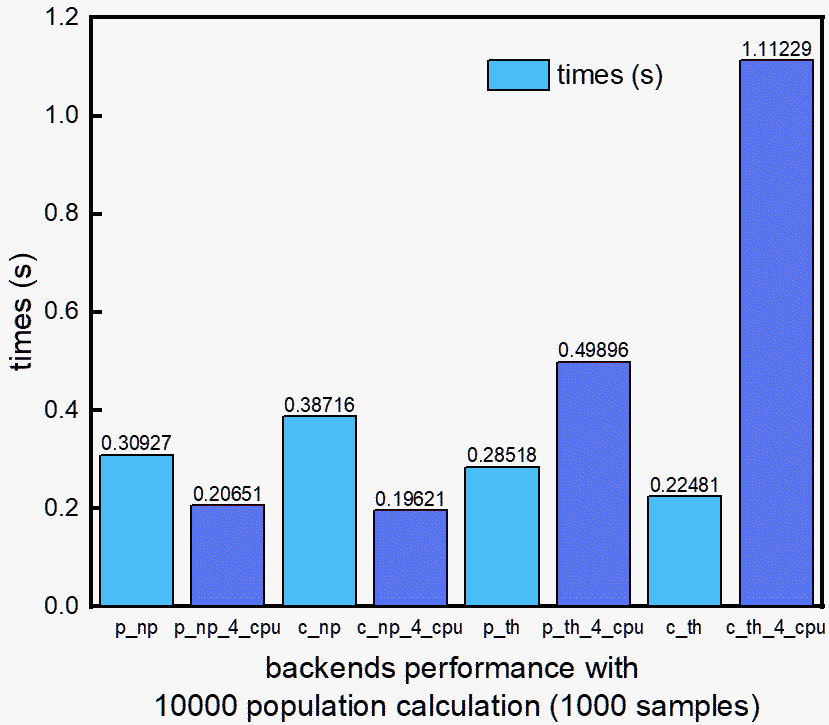
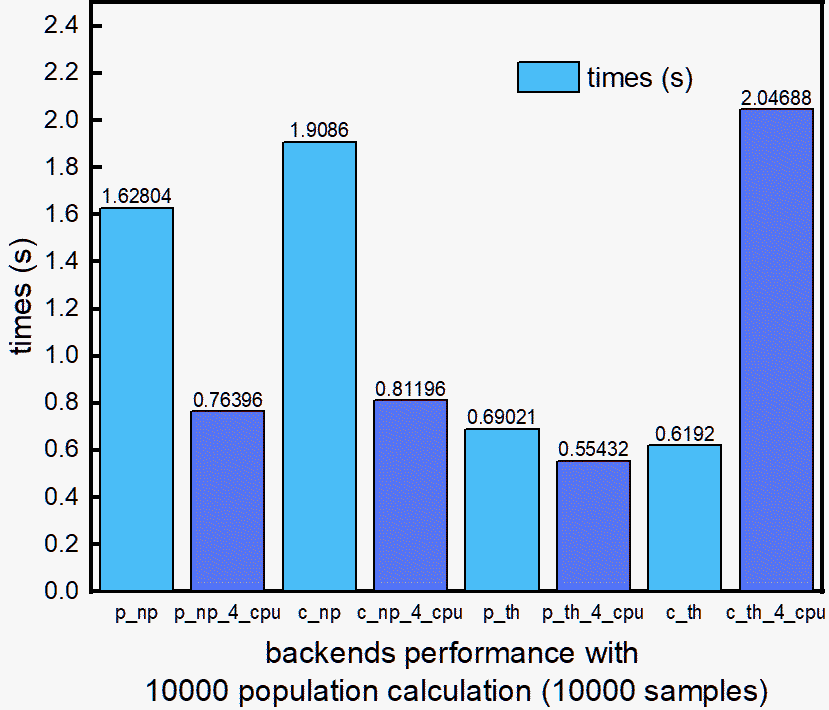
Backend Comparison¶
This comparison for different backend and their parallelization performance.
Conclusion
For large
samplesdatasets (more than 1000),torch>numpy.For any
populationvariation,numpy>torch.For “c_torch”, keep n_jobs==1. c_torch is already well parallelized in c++ level, and does not need to be parallelized in python code.
Code
>>> np.random.seed(0)
>>> deps = generate_random(func_num=13, xs_num=10, pop_size=10000, depth_min=1, depth_max=3)
>>> deps = deps.tolist()
>>> "p_numpy"
>>> rs1 = p_np_score(deps, x, y, func_index=func_index)
>>> "p_numpy"
>>> rs2 = p_np_score_mp(deps, x, y, func_index=func_index, n_jobs=4)
>>> "c_numpy"
>>> rs3 = c_np_score(deps, x, y, func_index=func_index)
>>> "c_numpy"
>>> rs4 = c_np_score_mp(deps, x, y, func_index=func_index, n_jobs=4)
>>> "p_torch"
>>> rs1 = p_torch_score(deps, x2, y2, func_index=func_index)
>>> "p_torch"
>>> rs2 = p_torch_score_mp(deps, x2, y2, func_index=func_index, n_jobs=4)
>>> "c_torch"
>>> rs3 = c_torch_score(deps, x2, y2, func_index=func_index)
>>> "c_torch"
>>> rs4 = c_torch_score_mp(deps, x2, y2, func_index=func_index, n_jobs=4)